





L'histoire de Barracuda Active Threat Intelligence
Il y a quelque temps, lors d'une de nos sessions de brainstorming, pendant laquelle les équipes ont discuté du prochain niveau d'évolution de nos produits, il est devenu évident qu'une analyse poussée des données à grande échelle serait nécessaire pour détecter les menaces modernes et émergentes, et s'en prémunir. Il fallait que cette analyse anticipe les risques encourus par les clients, et ce, de manière rapide et efficace afin de bloquer toute action malveillante.
En analysant les exigences, nous avons constaté que pour fournir une protection contre les pirates avancés comme les bots, nous devions créer une plateforme capable d'analyser le trafic des sessions Web, de le corréler avec les données de toutes les sessions, et ce, pour de nombreuses choses, dans l'ensemble de la base de clients. Nous avons également observé que de nombreuses parties du système devaient être en temps réel, d'autres en temps quasi réel et que d'autres encore pouvaient avoir une phase d'analyse beaucoup plus longue.
Il y a quelques années, nous avons lancé Barracuda Advanced Threat Protection (BATP) pour la protection contre les attaques de malwares de type zero-day dans la gamme de produits Barracuda. Cette fonctionnalité (qui en plus du sandboxing, analyse les fichiers pour détecter les malware à l'aide de plusieurs moteurs) a été ajoutée dans les produits de sécurité des applications de Barracuda pour sécuriser des applications telles que les systèmes de traitement des commandes où les fichiers sont téléchargés par des tiers. Il s'agissait de la première tentative d'utilisation d'une couche cloud pour effectuer une analyse avancée qu'il aurait été difficile d'intégrer dans des appliances Web Application Firewall.
Bien que la couche cloud BATP puisse gérer des millions d'analyses de fichiers, nous avions besoin d'un système capable de stocker une quantité importante de métadonnées afin de les analyser et détecter les menaces modernes et évolutives. Cela fut une première étape vers la création de la prochaine plateforme de suivi des menaces.
Comment fonctionne le suivi actif des menaces
La plateforme de suivi actif des menaces de Barracuda est notre solution au problème. Cette plateforme repose sur un gigantesque data lake, qui peut gérer le traitement des flux et le traitement par lots de données. Elle traite des millions d'événements par minute dans toutes les régions du monde, et fournit des renseignements utilisés pour détecter les bots et les attaques côté client, ainsi que des informations pour se protéger contre ces vecteurs de menace. Le suivi actif des menaces de Barracuda est conçu avec une architecture ouverte capable d'évoluer rapidement pour répondre aux nouvelles menaces.
Aujourd'hui, la plateforme de suivi actif des menaces de Barracuda reçoit des données des moteurs de sécurité du Web Application Firewall et du WAF-as-a-Service de Barracuda, ainsi que d'autres sources. Lorsqu'ils sont reçus, les événements sont complétés par des flux de menaces obtenus par crowdsourcing et d'autres bases de données de renseignements. L'analyse détaillée de ces événements, à la fois individuellement et dans le cadre d'une session utilisateur, permet de classer les clients en tant qu'êtres humains ou bots.
Les pipelines d'analyse des données utilisent divers moteurs et modèles de machine learning pour analyser les multiples aspects du trafic et formuler leurs recommandations, qui sont ensuite réconciliées pour produire le verdict final.
Les façons dont le suivi actif des menaces contribue à protéger vos applications
En plus de prendre en charge toutes les analyses requises pour Advanced Bot Protection, la plateforme de suivi actif des menaces est utilisée dans nos dernières offres : la protection côté client et le moteur de configuration automatisé.
Le suivi actif des menaces concerne toutes les ressources externes pouvant être utilisées par l'application, comme un JavaScript externe ou une feuille de style. Le suivi des ressources externes nous permet de connaître la surface des menaces et de fournir une protection contre des attaques comme Magecart, entre autres.
Les métadonnées collectées étant extrêmement riches, nous pouvons en tirer des informations supplémentaires pour aider les administrateurs en leur fournissant des recommandations de configuration basées sur le trafic réel arrivant sur leurs applications.
Cette plateforme a joué un rôle essentiel dans le développement des fonctionnalités de protection nouvelle génération dont nos clients ont besoin. Nous continuons de tirer parti de cette plateforme évolutive pour recueillir des informations détaillées sur les modèles de trafic, l'utilisation des applications, et plus encore. Ne manquez pas les articles de blog de nos équipes d'ingénierie qui vous expliqueront comment nous avons développé le suivi actif des menaces de Barracuda.

Anshuman Singh est directeur senior de la gestion des produits chez Barracuda. Connectez-vous avec lui sur LinkedIn ici.
L'évolution du pipeline de données
Le pipeline de données est le pilier central des applications consommant un volume élevé de données. Dans le premier article de cette série, nous nous pencherons sur l'histoire de ce pipeline de données ainsi que l'évolution de ces technologies à travers le temps. Nous examinerons ensuite la manière dont Barracuda exploite certains de ces systèmes, les éléments à prendre en compte lors de l'évaluation des composants du pipeline de données ainsi que des exemples d'applications pour vous aider à développer et déployer ces technologies.

MapReduce
En 2004, Jeff Dean et Sanjay Ghemawat de Google ont publié MapReduce: Simplified Data Processing on Large Clusters. Dans cette étude, ils donnent la définition suivante de MapReduce :
« […] un modèle de programmation et une implémentation associée permettant de traiter et générer des ensembles volumineux de données. Les utilisateurs définissent une fonction Map, qui traite une paire clé/valeur afin de générer un ensemble de paires clé/valeur intermédiaires, ainsi qu'une fonction Reduce qui se charge de fusionner toutes les valeurs intermédiaires associées à une même clé intermédiaire. »
En s'appuyant sur le modèle MapReduce, les deux informaticiens parviennent à simplifier la charge de travail parallèle sur laquelle reposaient les index Web de Google. Cette charge de travail est programmée sur un cluster de nœuds et capable d'évoluer au rythme du Web.
Lorsque l'on s'intéresse au modèle MapReduce, il est notamment important d'examiner où et comment sont stockées les données dans le cluster, un système auquel Google a donné le nom de Google File System (GFS). Le projet Apache Nutch permettra de donner vie à une alternative open source de MapReduce appelée Hadoop et développée à partir d'une implémentation open source de GFS. Hadoop est pour la première fois proposé par Yahoo! en 2006. (Hadoop est ainsi nommé en hommage au doudou du fils de Doug Cutting, un éléphant en peluche.)
Apache Hadoop : une implémentation open-source de MapReduce
![]()
Hadoop remporte un franc succès et les développeurs introduisent bientôt des abstractions permettant de définir des tâches à un plus haut niveau. Là où, par le passé, les fonctions Input, Map, Combine et Reduce étaient définies de manière très conventionnée (généralement en langage Java simple), les utilisateurs ont désormais la possibilité de concevoir des pipelines de données à partir de sources, récepteurs et opérateurs communs avec Cascading. À l'aide de la plateforme Pig, les développeurs peuvent également définir des tâches à un niveau encore plus élevé en utilisant un tout nouveau langage appelé le Pig Latin. Calculez et comparez ainsi le nombre de mots dans Hadoop, Cascading (2007) et Pig (2008).
Apache Spark : un moteur d'analyse unifié pour un traitement des données à grande échelle
C'est en 2009 que Matei Zaharia, alors étudiant à l'université de Berkeley, commence à développer Spark. En 2010, son équipe publie Spark: Cluster Computing with Working Sets, où elle détaille une méthode permettant de réutiliser un ensemble de données pour différentes opérations parallèles, et dévoile la première version publique de Spark en mars cette même année. En 2012, l'article Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing fait suite à cette première publication et remporte le prix de la meilleure publication lors du sommet USENIX Symposium on Networked Systems Design and Implementation. Dans cette publication, on découvre une nouvelle approche, nommée « Resilient Distributed Datasets » (RDD). Celle-ci permet aux programmeurs d'effectuer des calculs en mémoire pour appliquer des ordres de grandeur à des algorithmes itératifs comme PageRank afin d'accroître leurs performances ou d'exploiter le machine learning pour le même type de tâches conçues sur Hadoop.
Outre les gains de performance pour les algorithmes itératifs, Spark permet également pour la première fois d'exécuter des requêtes interactives, une innovation majeure. Spark exploite ainsi un interpréteur Scala interactif pour permettre aux data scientists d'interagir avec le cluster et d'exploiter de grands ensembles de données bien plus rapidement qu'en utilisant l'approche traditionnelle consistant à compiler et soumettre une tâche Hadoop, puis à attendre les résultats.
Un problème demeure toutefois : seules les données d'une source liée sont prises en compte dans le cadre des tâches Hadoop ou Spark (et non les nouvelles données entrantes au moment de l'exécution). La tâche est associée à une source d'entrée, qui détermine la façon dont celle-ci sera décomposée en segments ou tâches parallèles, exécute simultanément les tâches sur le cluster, puis combine les résultats et les enregistre quelque part. Cette approche fonctionne à merveille pour des tâches telles que la création d'index PageRank ou la régression logistique, mais s'avère inadaptée pour de nombreuses autres tâches s'exécutant sur une source non liée ou en continu, comme l'analyse du flux de clics (ou « click-stream ») et la prévention des fraudes.
Apache Kafka : une plateforme de streaming distribuée
En 2010, l'équipe d'ingénieurs de LinkedIn entreprend de réorganiser la technologie sous-jacente du réseau social professionnel [A Brief History of Kafka, LinkedIn’s Messaging Platform]. Comme bon nombre de sites Web, LinkedIn est passé d'une architecture monolithique à une architecture microservices interconnectée, mais c'est l'adoption d'une nouvelle architecture basée sur un pipeline universel lui-même conçu sur un journal de validation distribué appelé Kafka qui permet à LinkedIn de traiter ses flux d'événements en temps quasi réel et à une échelle considérable. Kafka est ainsi nommé par Jay Kreps, ingénieur principal de LinkedIn, car il s'agit d'un « système optimisé pour l'écriture » et Jay apprécie tout particulièrement les œuvres de Franz Kafka.
LinkedIn crée, en premier lieu, Kafka avec l'objectif de découpler ses microservices existants et ainsi leur permettre d'évoluer plus librement et indépendamment. Avant l'arrivée de sa plateforme de streaming distribuée, le schéma ou protocole utilisé pour permettre aux services de communiquer entre eux avait en effet condamné ces services à une évolution parallèle. L'équipe chargée de l'infrastructure de LinkedIn avait donc compris qu'il leur fallait disposer d'une grande flexibilité pour faire évoluer ses services de manière indépendante. Ils conçoivent ainsi Kafka afin de permettre à leurs services de communiquer de manière asynchrone et basée sur les messages. Cette plateforme doit être à la fois durable (persistance des messages sur disque) et tolérante aux défaillances de nœuds et réseau tout en offrant des caractéristiques en temps quasi réel et une évolutivité horizontale pour s'adapter à la croissance. Kafka répond à ces besoins en fournissant un journal distribué (voir The Log: What every software engineer should know about real-time data's unifying abstraction).
En 2011, Kafka est proposé en open source et adopté par de très nombreuses entreprises. Kafka offre plusieurs innovations par rapport aux précédentes abstractions de file d'attente de messages ou pub-sub telles que RabbitMQ et HornetQ :
- Les topics (files d'attente) Kafka sont partitionnés et répliqués sur un cluster de nœuds Kafka (appelés brokers).
- Kafka utilise ZooKeeper pour garantir la coordination, la haute disponibilité et le failover des clusters.
- Les messages persistent sur disque pendant de très longues périodes.
- Les messages sont consommés dans l'ordre.
- Les consommateurs sont chargés du maintien de leur état de consommation (offset du dernier message consommé).
Les systèmes producteurs n'ont ainsi pas à maintenir l'état de consommation de chaque message et peuvent désormais être transmis au système de fichiers à un rythme élevé. Les consommateurs étant chargés du maintien de leur propre offset au sein du topic, ils peuvent ainsi prendre en charge les mises à jour et défaillances de manière optimale.
Apache Storm : système de calcul en temps réel distribué
Parallèlement, en mai 2011, Nathan Marz finalise l'acquisition de sa société BackType par Twitter. BackType « concevait des produits d'analyse pensés pour aider les entreprises à comprendre leur impact historique et en temps réel sur les médias sociaux » [History of Apache Storm and Lessons Learned]. L'un des joyaux de BackType était un système de traitement en temps réel nommé « Storm ». Storm fournit une abstraction, appelée « topologie », qui simplifie les opérations sur les flux de la même façon que MapReduce facilite le traitement par lot. Storm est ainsi présenté comme un « Hadoop en temps réel » et se retrouve rapidement au cœur de toutes les conversations sur GitHub et Hacker News.
Apache Flink : calculs avec état sur les flux de données
Flink est également dévoilé au public en mai 2011. Ce framework est issu du projet de recherche académique « Stratosphere » [http://stratosphere.eu/], collaboration entre une poignée d'universités allemandes. Stratosphere doit permettre « d'optimiser le traitement parallèle de volumes de données élevés sur des plateformes IaaS (Infrastructure as a Service (IaaS) » [http://www.hpcc.unical.it/hpc2012/pdfs/kao.pdf].
À l'instar de Storm, Flink offre un modèle de programmation permettant de traiter des « jobs » (flux de données) incluant un ensemble de flux et de transformations. Flink fournit également un moteur d'exécution capable de traiter efficacement le job de manière parallèle et de le programmer sur un cluster géré. Le modèle de programmation de Flink présente la spécificité d'admettre à la fois les sources de données liées et non liées. La syntaxe d'un job à exécuter une fois traitant des données depuis une base SQL (traditionnellement associé à un traitement par lot) et celle d'un job à exécuter en continu sur des données en flux issues d'un topic Kafka sont donc proches. Flink intègre le projet d'incubation Apache en mars 2014 et est accepté en tant que Top-Level Project (projet de premier plan) Apache en décembre 2014.
En février 2013, la version alpha de Spark Streaming est introduite avec Spark 0.7.0. En septembre 2013, l'équipe LinkedIn rend disponible son framework de traitement de flux, nommé « Samza », avec cette publication.
En mai 2014, Spark 1.0.0 est publié et introduit Spark SQL. Si cette version offre des capacités de diffusion limitée (la source de données doit être divisée en « micro-lots »), les bases d'une exécution en flux des requêtes SQL sont bien présentes.
Apache Beam : un modèle de programmation unifié pour le traitement par flux ou par lots
En 2015, un collectif d'ingénieurs de Google publie un article intitulé The Dataflow Model: A Practical Approach to Balancing Correctness, Latency, and Cost in Massive-Scale, Unbounded, Out-of-Order Data Processing. Un an plus tôt, en 2014, une implémentation du modèle Dataflow était dévoilée sur Google Cloud Platform. En 2016, Google fait don à Apache du SDK de base de ce projet ainsi que de plusieurs connecteurs E/S et d'un exécuteur local. La première version d'Apache Beam est publiée en juin, la même année.
L'un des principaux avantages du modèle Dataflow (et Apache Beam) est qu'il permet de créer des pipelines sans se soucier du moteur d'exécution. Lors de l'écriture, Beam peut ainsi compiler le même code, qu'il cible Flink, Spark, Samza, GearPump, Google Cloud Dataflow ou Apex. Par conséquent, l'utilisateur est libre de changer de moteur d'exécution sans avoir à prévoir de ré-implémentation. Un moteur d'exécution « Direct Runner » est également disponible pour les tests et développements dans l'environnement local.
En 2016, l'équipe de développement de Flink présente Flink SQL. Kafka SQL est annoncé en août 2017 et, en mai 2019, un groupe d'ingénieurs Apache Beam, Apache Calcite et Apache Flink publie « One SQL to Rule Them All: An Efficient and Syntactically Idiomatic Approach to Management of Streams and Tables », un article en faveur d'un SQL unifié.
Où en sommes-nous aujourd'hui ?
Les outils mis à la disposition des architectes logiciel chargés du pipeline de données continuent d'évoluer à un rythme impressionnant. De nouveaux moteurs de flux de travail, tels qu'Airflow et Prefect, et systèmes d'intégration comme Dask permettent aujourd'hui aux utilisateurs de paralléliser et programmer de grands volumes de charges de travail de machine learning sur le cluster. De nouveaux concurrents comme Apache Pulsar et Pravega s'opposent à Kafka sur le terrain de l'abstraction du stockage du flux. Des projets comme Dagster, Kafka Connect et Siddhi intègrent des composants existants tout en proposant des approches inédites en matière de visualisation et conception du pipeline de données. Avec ces avancées rapides, la conception d'applications consommant des volumes considérables de données nous réserve encore bien des surprises.
Envie de travailler avec ce type de technologie ? Contactez-nous ! Nous avons de multiples postes d'ingénieurs à pourvoir dans plusieurs régions du monde.

Robert Boyd est Principal Software Engineer chez Barracuda Networks. Il se concentre actuellement sur le stockage et la recherche sécurisés des e-mails à grande échelle.
Favoris des lecteurs en 2021
La fin d'année est la période idéale pour présenter certains de nos contenus favoris. Voici les billets de blog Barracuda les plus populaires en 2020. En espérant qu'ils vous plaisent !
Ransomware et violations de données
- Comment les hackers utilisent le phishing dans les attaques de ransomware
- Principales préoccupations des organismes de santé concernant la sauvegarde d'Office 365.
- 3 étapes critiques pour se protéger contre les ransomwares
- La cyberattaque de Colonial Pipeline révèle l'impact économique des ransomwares
Recherche
- Types de menaces par e-mail : le phishing par URL
- Threat Spotlight : tendances des ransomwares
- Zoom sur les menaces : Attaques par appât
Rapports spéciaux
- L'état de la sécurité des réseaux en 2021
- La sécurité des applications : état des lieux en 2021
- Réseaux cloud : uen accélération de la transition
- Sauvegarde Office 365 : état des lieux
- Un aperçu du nombre croissant d'attaques automatisées
Below the Surface
- Below the Surface : Pourquoi vous avez besoin d'une stratégie de sauvegarde cloud-native
- Below the surface : Faire progresser les femmes dans le domaine de la technologie
- Below the surface : Service d'accès sécurisé Edge avec Sinan Eren
Barracuda
- Barracuda a été nommé Visionnaire en 2021 dans le Gartner® Magic Quadrant™
 pour les pare-feux réseau
pour les pare-feux réseau - Barracuda a été récompensé par Comparably for Best Company Culture
- 3 innovations produit passionnantes annoncées chez Secured.21
- Les coulisses de la collaboration entre Barracuda et Microsoft sur Cloud-to-Cloud Backup
- Barracuda nommé au palmarès Security 100 de CRN pour l'année 2021
- Barracuda remporte le prix du meilleur service client lors des SC Awards 2021
Anciens favoris
Certaines questions persistent. Pourquoi ne puis-je pas utiliser mon adresse e-mail personnelle pour travailler ? Qu'entendez-vous par « ce spam n'en n'est pas un » ? Ces articles restent les préférés des lecteurs année après année.
- Les comptes e-mail personnels : un danger pour l'entreprise
- Ham vs Spam : quelle est la différence ?
- Vecteurs de menace : pourquoi est-il important de les connaître ?
Nous attendons l'année 2022 avec impatience !
Nos experts vont présenter des contenus encore plus pertinents, parmi eux Olesia, Tushar, Anastasia, Jonathan, Fleming, etc. Nous mettons plusieurs publications en ligne chaque semaine, et si vous souhaitez être notifié(e) de tout nouveau contenu, veuillez vous abonner à notre blog pour recevoir des récapitulatifs des derniers billets par e-mail. De nouveaux épisodes de Below the Surface sont diffusés toutes les deux ou trois semaines et vous pouvez visionner les épisodes archivés sur notre site internet.
Toute l'équipe Barracuda vous adresse ses meilleurs vœux et vous souhaite une bonne année.

Christine Barry est Senior Chief Blogger et Social Media Manager chez Barracuda. Avant de rejoindre Barracuda, Christine a été ingénieure de terrain et chef de projet dans l'éducation et auprès de PME pendant plus de 15 ans. Elle est titulaire de plusieurs diplômes en technologie et en gestion de projet, d'un "Bachelor of Arts" et d'un "Master of Business Administration".Elle est diplômée de l'université du Michigan.
Connectez-vous avec Christine sur LinkedIn.
Enregistrement d'événements à grande échelle sur AWS
La plupart des applications génèrent des événements de configuration et d'accès, que les administrateurs doivent pouvoir visualiser. Le service Barracuda Email Security offre une plus grande transparence et visibilité sur tous ces événements pour aider les administrateurs à ajuster et comprendre leur système. Il vous permet notamment de connaître l'identité des utilisateurs connectés à un compte ainsi que le moment où ils se connectent ou encore d'identifier la personne qui a ajouté, modifié ou supprimé la configuration d'une politique spécifique.
Développer un tel système distribué et interrogeable requière de se poser plusieurs questions, parmi lesquelles :
- Comment extraire ces enregistrements de l'ensemble de vos applications, services et machines pour les envoyer vers un emplacement centralisé ?
- Quel doit être le format standard de ces fichiers journaux ?
- Combien de temps devrez-vous conserver ces journaux ?
- Comment relier les événements provenant de différentes applications ?
- Comment proposer à l'administrateur un mécanisme de recherche à la fois simple et rapide, accessible depuis une interface utilisateur ?
- Comment permettre l'accès à ces journaux via une API ?
Elasticsearch est la première solution qui nous vient à l'esprit lorsque l'on pense à un moteur de recherche distribué. Hautement évolutif, il permet une recherche en temps quasi réel et est disponible en tant que service entièrement géré via AWS. Pour cet exemple, nous allons donc enregistrer nos journaux d'événements dans Elasticsearch, et Kinesis Data Firehose assurera leur transfert depuis les différentes applications jusqu'à notre moteur de recherche.
Les composants de cette architecture
- Kinesis Agent – Kinesis Agent d'Amazon est une application logicielle Java autonome qui vous permet de collecter et d'envoyer facilement des données vers Kinesis Data Firehose. Cet agent assure un suivi continu des fichiers journaux d'événements dans les instances EC2 Linux et les transfère vers le flux de diffusion Kinesis Data Firehose configuré. L'agent gère ainsi la rotation des fichiers, les points de contrôle et les nouvelles tentatives après échec pour vous fournir toutes les données dont vous avez besoin de manière fiable, rapide et simple. Notez toutefois qu'un conteneur Fluentd sera nécessaire si l'application qui doit écrire dans Kinesis Firehose est un conteneur Fargate. Cependant, cet article se concentre sur les applications exécutées sur des instances Amazon EC2.
- Kinesis Data Firehose – La méthode Direct PUT d'Amazon Kinesis Data Firehose permet d'écrire des données au format JSON dans Elasticsearch, sans qu'aucune donnée ne soit stockée dans le flux.
- S3 – Un compartiment S3 peut être utilisé pour sauvegarder la totalité des enregistrements ou seulement ceux dont l'envoi vers Elasticsearch a échoué. Il est également possible de créer des politiques de cycle de vie afin d'automatiser l'archivage des journaux.
- Elasticsearch – Elasticsearch hébergé par Amazon. L'accès à Kibana peut être activé afin de simplifier la requête et la recherche de journaux à des fins de débogage.
- Curator – AWS recommande d'utiliser Lambda et Curator pour gérer les index et instantanés du cluster Elasticsearch. De plus amples informations et un exemple de code sont proposés par AWS ici.
- Interface API REST – Vous pouvez créer une API qui fera office de couche d'abstraction pour Elasticsearch tout en s'intégrant parfaitement à l'interface utilisateur. Les architectures de microservices par API sont réputées pour leurs performances élevées, notamment en matière de sécurité et de conformité, ainsi que pour leur intégration optimale avec d'autres services.

Évolutivité
- Kinesis Data Firehose : par défaut, les flux de diffusion Firehose peuvent traiter jusqu'à 1 000 enregistrements par seconde ou 1 Mio par seconde dans la région USA Est (Ohio). Cette limite n'est toutefois pas stricte et peut être étendue jusqu'à 10 000 enregistrements par seconde. Ce nombre varie en fonction des régions.
- Elasticsearch : les capacités de stockage et la puissance de calcul du cluster Elasticsearch peuvent être étendues dans AWS. Des mises à niveau sont également disponibles. Amazon ES fait appel à un flux de déploiement Blue-Green pour la mise à jour des domaines. Par conséquent, le nombre de nœuds contenus dans le cluster est susceptible de croître temporairement lorsque des modifications sont appliquées.
Les avantages de cette architecture
- L'architecture de pipeline est entièrement gérée, demandant très peu de maintenance.
- En cas d'échec du cluster Elasticsearch, Kinesis Firehose peut conserver les enregistrements pendant 24 heures. En outre, les enregistrements qui ne peuvent pas être transmis sont également sauvegardés dans S3.
Les risques de perte de données sont ainsi moindres.
- Les politiques de gestion des identités et des accès (IAM) permettent un contrôle strict des accès aux API Kibana et Elasticsearch.
Les limites
- La question du tarif doit être soigneusement étudiée et surveillée. Kinesis Data Firehose est capable d'absorber sans difficulté de larges volumes de données et si un acteur non autorisé commence à journaliser un grand nombre de données, le service les diffusera. Attention, les frais occasionnés peuvent être élevés.
- L'intégration Kinesis Data Firehose vers Elasticsearch est uniquement compatible avec les clusters Elasticsearch non VPC.
- Kinesis Data Firehose ne prend actuellement pas en charge la diffusion de journaux vers des clusters Elasticsearch non hébergés par AWS. Cette configuration n'est pas non plus compatible avec l'auto-hébergement de clusters Elasticsearch.
Conclusion
Si vous êtes en quête d'une solution entièrement gérée et capable d'évoluer sans que vous n'ayez à intervenir (ou très peu), cette option est tout à fait adaptée. Le backup automatique sur S3 et les politiques de cycle de vie apportent, de plus, une réponse simple à la question de la conservation et de l'archivage des journaux.

Sravanthi Gottipati est responsable de l'ingénierie pour la sécurité des e-mails chez Barracuda Networks. Vous pouvez vous connecter avec elle sur LinkedIn ici.
DJANGO-EB-SQS : la communication entre les applications Django et AWS SQS devient un jeu d'enfant
Les services AWS comme Amazon ECS, Amazon S3, Amazon Kinesis, Amazon SQS et Amazon RDS sont fréquemment exploités dans le monde entier. Chez Barracuda, nous utilisons AWS Simple Queue Service (SQS) pour gérer la messagerie au sein et parmi les microservices que nous avons développés sur le cadre Django.
AWS SQS est un service de gestion des messages en attente qui permet « d'envoyer, de stocker et de recevoir des messages entre des composants logiciels, quel que soit le volume, sans risque de perdre des messages ou de nécessiter le recours à d'autres services. » SQS est conçu pour aider les entreprises à dissocier les applications et à faire évoluer les services, et c'était l'outil idéal pour nos projets portant sur les microservices. Cependant, chaque nouveau microservice basé sur Django ou la dissociation d'un service existant à l'aide d'AWS SQS exigeait que nous dupliquions notre code et notre logique pour communiquer avec AWS SQS. Cela a donné lieu à de nombreuses répétitions de code et a motivé notre équipe à créer cette bibliothèque GitHub : DJANGO-EB-SQS
La bibliothèque python Django-EB-SQS a été conçue pour aider les développeurs à intégrer rapidement AWS SQS avec des applications existantes et/ou nouvelles basées sur Django. La bibliothèque se charge des tâches suivantes :
- Sérialisation des données
- Ajout d'une logique de report
- Vérification de la file d'attente en permanence
- Désérialisation des données conformément aux normes AWS SQS et/ou utilisation de bibliothèques tierces pour communiquer avec AWS SQS.
En bref, il fait abstraction de toute la complexité liée à la communication avec AWS SQS et permet aux développeurs de se concentrer uniquement sur la logique commerciale principale.
La bibliothèque est basée sur le cadre Django ORM et la bibliothèque boto3.
Comment nous l'utilisons
Notre équipe travaille sur une solution de protection des e-mails qui utilise l'intelligence artificielle pour détecter le spear phishing et d'autres attaques de Social Engineering. Nous nous intégrons au compte Office 365 de nos clients, qui reçoivent des notifications dès qu'ils reçoivent de nouveaux e-mails. L'une des tâches consiste à déterminer si le nouvel e-mail est exempt de toute possibilité de fraude ou non. À la réception de ces notifications, l'un de nos services (Figure 1 : Service 1) communique avec Office 365 via Graph API et reçoit ces e-mails. Pour le traitement ultérieur de ces e-mails et pour rendre les e-mails accessibles à d'autres services, ces e-mails sont ensuite transférés vers la file d'attente AWS SQS (Figure 1 : queue_1).

Figure 1
Examinons un cas d'utilisation simple sur la façon dont nous utilisons la bibliothèque au sein de nos solutions. L'un de nos services (Figure 1 : Service 2) est chargé d'extraire les en-têtes et les ensembles de fonctionnalités des e-mails individuels et de les mettre à la disposition des autres services.
Le service 2 est configuré pour surveiller la queue_1 afin de récupérer les corps bruts des e-mails.
Supposons que le Service 2 effectue les actions suivantes :
# consomme les e-mails de la queue_1
…
# extrait les en-têtes et les ensembles de fonctionnalités des e-mails
…
# soumet une tâche
process_message.delay(tenant_id=, email_id=, headers=, tenant_id=, feature_set=, ….)
Cette méthode process_message ne sera pas sollicitée de manière synchrone, elle sera placée en attente en tant que tâche et sera exécutée dès que l'un des employés la traitera. L'employé peut appartenir au même service ou à un service différent. Le commanditaire de la méthode n'aura pas à se soucier du comportement sous-jacent et de la manière dont la tâche sera exécutée.
Voyons comment définir la méthode process_message comme une tâche.
depuis le fichier d'importation de tâches eb_sqs.decorators
@task(queue_name='queue_2′, max_retries=3)
def process_message(tenant_id: int, email_id: str, headers: List[dict], feature_set: List[dict], …) :
essayer :
# exécute une action en utilisant des en-têtes et des ensemble de fonctionnalités
# peut également mettre d'autres tâches en file d'attente, si nécessaire
sauf(OperationalError, InterfaceError) comme exc :
essayer :
process_message.retry()
sauf MaxRetriesReachedException :
logger.error(‘MaxRetries reached for Service2:process_message ex: {exc}')
Lorsque nous décorons la méthode avec le décorateur de tâche, ce qui se passe ensuite est qu'il ajoute des données supplémentaires comme la méthode appelante, la méthode cible, ses paramètres et quelques métadonnées supplémentaires avant de sérialiser le message et de le transférer vers la file d'attente AWS SQS. Lorsque le message est extrait depuis la file d'attente par l'un des employés, il dispose de toutes les informations nécessaires à l'exécution de la tâche : quelle méthode appeler, quels paramètres utiliser, etc.
Nous pouvons également relancer la tâche si une exception survient. Toutefois, pour éviter un scénario sans fin, nous pouvons définir un paramètre facultatif max_retries qui nous permet de suspendre le traitement après avoir atteint le nombre maximal de tentatives. Nous pouvons alors consigner l'erreur ou envoyer la tâche dans une file d'attente de lettres mortes pour une analyse plus poussée.
AWS SQS offre la possibilité de retarder le traitement du message jusqu'à 15 minutes. Nous pouvons ajouter une fonctionnalité similaire à notre tâche en précisant le paramètre de retard :
process_message.delay(email_id=, headers=, …., delay=300) # retard de 5 minutes
L'exécution des tâches peut être effectuée en exécutant la commande Django process_queue. Cela permet de gérer l'écoute d'une ou de plusieurs files d'attente, de les consulter en permanence et d'exécuter les tâches au fur et à mesure qu'elles arrivent :
python manage.py process_queue –files d'attente
Nous venons de découvrir comment cette bibliothèque facilitait la communication au sein d'un service ou entre des services via les files d'attente AWS SQS.
Pour plus de détails sur la configuration de la bibliothèque avec les paramètres Django, la possibilité de gérer plusieurs files d'attente, la configuration du développement et bien d'autres fonctionnalités, cliquez ici.
Contribuer
Si vous souhaitez contribuer au projet, veuillez vous rendre ici : DJANGO-EB-SQS

Rohan Patil est ingénieur logiciel principal chez Barracuda Networks. Il travaille actuellement sur Barracuda Sentinel, une solution de protection basée sur l'IA contre le phishing et le piratage de compte. Il a travaillé ces cinq dernières années sur les technologies cloud et ces dix dernières années, il a occupé divers postes dans le domaine du développement de logiciels. Il est titulaire d'un master en informatique de l'Université d'État de Californie et d'un bachelor en informatique de Mumbai, en Inde.
Créer des API robustes et flexibles avec GraphQL
La conception des API est un domaine dans lequel il peut y avoir beaucoup de conflits entre les développeurs d'applications clientes et les développeurs backend. Les API REST nous ont permis de concevoir des serveurs sans statut et un accès structuré aux ressources pendant plus de deux décennies, et elles continuent de répondre aux besoins du secteur, principalement en raison de leur simplicité et de leur courbe d'apprentissage modérée.
REST a été développé aux alentours de l'an 2000, lorsque les applications client étaient relativement simples et que les évolutions n'étaient pas aussi nombreuses qu'aujourd'hui.
Avec une approche traditionnelle basée sur REST, la conception serait basée sur un concept de ressources gérées par un serveur donné. Ensuite, nous nous appuyons généralement sur des verbes HTTP tels que GET, POST, PATCH, DELETE pour effectuer des opérations CRUD sur ces ressources.
Depuis les années 2000, bien des choses ont changé :
- L'utilisation accrue d'applications à page unique et d'applications mobiles a créé un besoin de téléchargement efficace des données.
- De nombreuses architectures backend ont délaissé les architectures monolithiques au profit d'architectures µservice pour des cycles de développement plus rapides et plus performants.
- Une grande variété de clients et de consommateurs sont nécessaires pour les API. REST rend difficile la construction d'une API prenant en charge plusieurs clients, car elle renverrait à une structure de données fixe.
- Les entreprises souhaitent déployer des fonctionnalités plus rapidement sur le marché. Si une modification doit être effectuée côté client, elle nécessite souvent un ajustement côté serveur avec REST, ce qui se traduit par des cycles de développement plus lents.
- L'attention accrue portée à l'expérience utilisateur conduit souvent à la conception de vues/widgets dont le rendu nécessite des données provenant de plusieurs serveurs de ressources API REST.
GraphQL comme alternative à REST
GraphQL est une alternative moderne à REST qui vise à remédier à plusieurs faiblesses. Son architecture et ses outils sont conçus pour offrir des solutions aux pratiques contemporaines de développement de logiciels. Elle permet aux clients de spécifier exactement les données dont ils ont besoin et permet d'extraire des données de plusieurs ressources en même temps. Elle fonctionne davantage comme un RPC, avec des requêtes et des mutations nommées et non des actions obligatoires classiques basées sur le protocole HTTP. Le contrôle est ainsi exercé conformément aux attentes, le développeur de l'API backend spécifiant ce qui est possible, et le client/consommateur de l'API spécifiant ce qui est requis.
Voici un exemple de requête GraphQL, qui a suscité un vif intérêt de ma part lorsque je l'ai découverte. Supposons que nous construisions un site de microblogging et que nous ayons besoin de faire une requête pour 50 messages récents.
query recentPosts(count: 50, offset: 0) {
id
title
tags
content
author {
id
name
profile {
email
interests
}
}
}
La requête GraphQL ci-dessus vise à demander :
- 50 articles récents
- Id, titre, balises et contenu de chaque article de blog
- Informations sur l'auteur incluant l'identifiant, le nom et les informations sur le profil.
Si nous devions utiliser une approche traditionnelle d'API REST pour cela, le client devrait effectuer 51 requêtes. Si les articles et les auteurs sont considérés comme des ressources distinctes, il faudrait une requête pour accéder à 50 articles récents, puis 50 requêtes pour obtenir les informations sur les auteurs de chaque article. Si les informations sur l'auteur peuvent être incluses dans les informations sur l'article, cela pourrait être une requête avec l'API REST également. Mais, dans la plupart des cas, lorsque nous modélisons nos données à l'aide des meilleures pratiques de normalisation des bases de données relationnelles, nous gérons les informations sur les auteurs dans un tableau distinct, ce qui implique que les informations sur les auteurs constituent une ressource API REST distincte.
Ce qui est intéressant avec GraphQL. Supposons que, sur un écran mobile, nous n'ayons pas assez de place pour afficher à la fois le contenu de l'article et les informations sur le profil de l'auteur. Cette requête pourrait être la suivante :
query recentPosts(count: 50, offset: 0) {
id
title
tags
author {
id
name
}
}
Le client sur le mobile spécifie maintenant les informations qu'il désire, et l'API GraphQL fournit les données exactes qu'il a demandées, ni plus ni moins. Nous n'avons pas eu à effectuer d'ajustements côté serveur, ni à modifier de manière significative notre code côté client, et le débit du réseau entre le client et le serveur reste optimal.
Ce qu'il faut retenir ici, c'est que GraphQL nous permet de concevoir des API flexibles en fonction des exigences du client et non pas du point de vue de la gestion des ressources du serveur. La croyance générale est que GraphQL n'a de sens que pour les architectures complexes impliquant plusieurs dizaines de µservices. C'est vrai dans une certaine mesure, étant donné que l'on observe une certaine courbe d'apprentissage avec GraphQL par rapport aux architectures d'API REST. Mais cela tend à changer, grâce à un investissement intellectuel et financier important de la part de la fondation émergente neutre vis-à-vis des fournisseurs.
Barracuda est l'un des premiers à adopter les architectures GraphQL. Si ce billet a suscité votre intérêt, je vous invite à suivre mes prochains billets où je me pencherai sur les détails techniques et les avantages architecturaux.

Vinay Patnana est le directeur technique du service de sécurité des e-mails de Barracuda. À ce poste, il participe à la conception et au développement des services d'évolutivité des solutions pour messagerie de Barracuda.
Vinay est titulaire d'un master en informatique de l'Université d'État de Caroline du Nord et d'un bachelor en ingénierie du BIT Mesra, en Inde. Il travaille chez Barracuda depuis plusieurs années et compte plus d'une dizaine d'années d'expérience à son actif sur plusieurs variétés de piles techniques. Vous pouvez le retrouver sur LinkedIn ici.
Remarque : cet article a été initialement publié sur le blog de la société Databricks.
74 % des entreprises dans le monde ont été victimes d'une attaque de phishing.Barracuda Networks est un leader mondial en matière de sécurité, de livraison d'applications et de solutions de protection des données, aidant les clients à lutter contre les attaques de phishing à grande échelle. Barracuda a mis au point un puissant moteur d'intelligence artificielle qui utilise l'analyse comportementale pour détecter les attaques et tenir les acteurs malveillants à distance.
Traiter les e-mails de phishing est difficile en raison de la sophistication des e-mails malveillants créés par les pirates aujourd'hui. Barracuda Networks utilise le Machine Learning pour évaluer et identifier les messages malveillants et protéger ses clients. En utilisant le ML sur la plateforme Lakehouse de Databricks, l'équipe de Barracuda a pu travailler beaucoup plus rapidement et bloque désormais des dizaines de milliers d'e-mails malveillants chaque jour, les empêchant d'atteindre des millions de boîtes mail chez des milliers de clients.
Fournir une protection complète des e-mails
L'équipe de Barracuda se consacre à la détection des attaques de phishing et à la sécurité de ses clients. L'entreprise y parvient en travaillant sur Microsoft Office 365 et en analysant le flux d'e-mails pour y déceler d'éventuelles menaces. Si une attaque est détectée, elle est immédiatement supprimée de la boîte mail avant que les utilisateurs ne s'en aperçoivent.
Protection contre l'usurpation d'identité
L'un des produits majeurs proposés par Barracuda est la protection contre l'usurpation d'identité. L'usurpation d'identité se produit lorsque des acteurs malveillants se font passer pour des sources officielles, comme un cadre dirigeant ou un service connu. Les pirates peuvent utiliser cette attaque pour accéder à des informations confidentielles, ce qui représente un risque important pour les particuliers comme pour les entreprises.
La protection contre l'usurpation d'identité vise à dissuader les attaques de phishing ciblées. Ces tentatives ne sont pas envoyées en grand nombre, contrairement aux spams. Pour envoyer une attaque ciblée, le pirate doit disposer d'informations personnelles sur le destinataire afin de la personnaliser, telles que sa profession ou son domaine de travail. Pour identifier et bloquer les attaques de phishing par usurpation d'identité, l'équipe a dû créer un ensemble de modèles de classification et les déployer en production pour nos utilisateurs.
Difficultés avec la conception des fonctionnalités
Afin de former correctement nos modèles d'IA à détecter les attaques de phishing et d'usurpation d'identité, Barracuda avait besoin d'utiliser les bonnes données et d'effectuer une conception des fonctionnalités en plus de ces données. Les données comprenaient le texte de l'e-mail, qui pourrait être un signal d'attaque de phishing, ainsi que des données statistiques, telles que les détails sur l'expéditeur de l'e-mail. Par exemple, si un utilisateur reçoit un e-mail contenant une facture de la part d'une personne qui n'a pas envoyé d'e-mail similaire au cours des derniers mois, cela peut signaler un risque d'attaque de phishing. Avant l'intégration avec Databricks, la création de fonctionnalités était plus difficile car les données étiquetées étaient réparties sur plusieurs mois, en particulier les fonctionnalités statistiques. De plus, il était difficile de suivre les fonctionnalités lorsque notre ensemble de données augmente considérablement.
Lenteur du déploiement
Notre équipe a séparé le code et la modélisation et a dû dupliquer le code de recherche pour l'environnement de production, ce qui a pris du temps et de l'énergie. Nous faisions d'abord passer chaque e-mail entrant par le code de prétraitement, puis nous transmettions les e-mails prétraités à la modélisation pour en tirer des conclusions.
Barracuda réussit grâce à Databricks
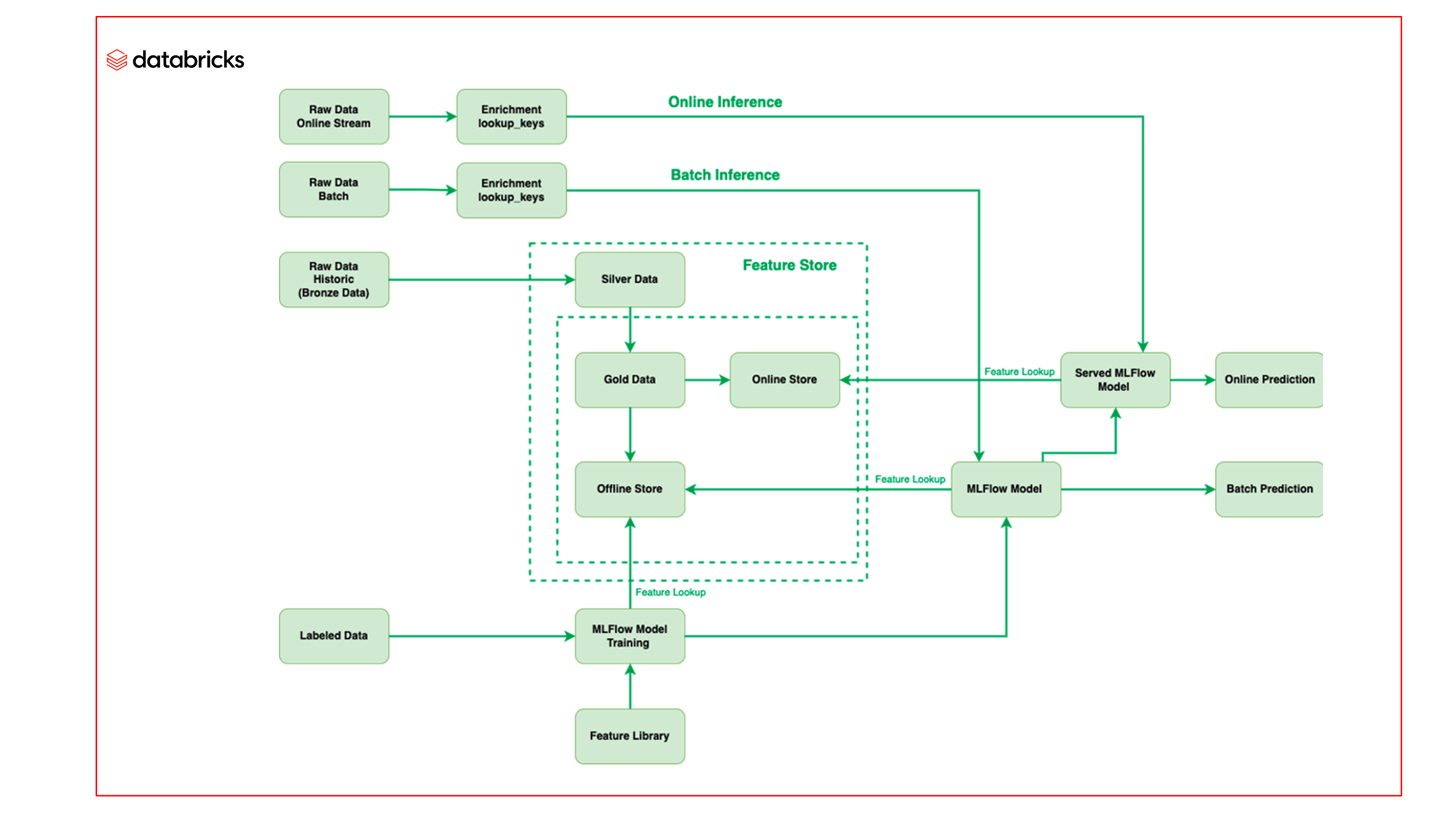
L'équipe de Barracuda a tiré parti du Machine Learning sur la plateforme Lakehouse de Databricks, en particulier en utilisant le Feature Store et Managed MLflow, pour améliorer le processus de ML et déployer plus rapidement des modélisations de meilleure qualité.

Feature Store
Databricks Feature Store sert de référentiel unique pour toutes les fonctionnalités utilisées par l'équipe de Barracuda. Pour créer et gérer des fonctionnalités statistiques constamment mises à jour avec de nouveaux lots d'e-mails entrants, les données étiquetées ont été utilisées dans la conception des fonctionnalités. Étant donné que Feature Store est construit sur Delta, aucun traitement supplémentaire n'est nécessaire pour convertir les données étiquetées en fonctionnalités et ces dernières restent à jour. Les fonctionnalités sont conservées dans un référentiel hors ligne et des résumés de ces informations sont ensuite diffusés en ligne pour être utilisés afin de tirer des conclusions en ligne. En outre, en intégrant Databricks Feature Store à MLflow, ces fonctionnalités peuvent être facilement appelées à partir des modélisations dans MLflow, et la modélisation peut obtenir la fonctionnalité en même temps que la récupération de la fonctionnalité lorsque l'e-mail arrive pour être traité.
Opérations de Machine Learning plus rapides
Autre avantage : la gestion de toutes les modélisations de Machine Learning dans MLflow. Avec MLflow, l'équipe peut déplacer tout le code dans la modélisation, et donc laisser l'e-mail passer par la modélisation pour être traité au lieu de le prétraiter par du code comme c'était le cas auparavant, ce qui permet de tirer des conclusions sur la nature de l'e-mail plus rapidement. En utilisant MLflow, l'équipe de Barracuda est en mesure de construire des modélisations entièrement autonomes. Cette capacité réduit considérablement le temps que l'équipe consacre au développement de modélisations de ML.
Taux de détection plus élevé
Avec Databricks, l'équipe dispose de plus de temps et de calculs qui lui permettent de publier fréquemment de nouvelles tables dans Delta, de mettre à jour les fonctionnalités chaque jour et de les utiliser pour savoir si un e-mail entrant est une attaque ou non. Cela se traduit par une plus grande précision dans la détection des attaques de phishing et l'amélioration de la protection et la satisfaction des clients.
Impact
Grâce à Databricks, Barracuda protège les utilisateurs contre les attaques par e-mail dans le monde entier. Chaque jour, l'équipe bloque des dizaines de milliers d'e-mails malveillants et les empêche de tomber dans les boîtes mail des clients. L'équipe a hâte de pouvoir continuer à implémenter de nouvelles fonctionnalités de Databricks pour améliorer davantage l'expérience de nos clients.

{kind=link}
Mohamed Afifi Ibrahim est ingénieur principal en machine learning chez Barracuda.